Apache Kafka
Kafka是由Apache軟體基金會開發的一個開源流處理平台,由Scala和Java編寫。
該專案的目標是為處理即時資料提供一個統一、高吞吐、低延遲的平台。
Kafka 主要有以下幾個核心名詞:
Topics
1
| 在 Kafka 中 topic 就像是 database 中的 table,為不同資料的類別名稱。
|
Partitions
1
2
| Topic 內切分為數個 Partitions,在 Kafka 中每個最小單位的訊息 (message) 或記錄 (record)
以序列 append 的方式存放在在每個 Partition 中,Partition 可以分散式的存放在不同機器中,以防止單台機器故障。
|
Producers and Consumers
1
2
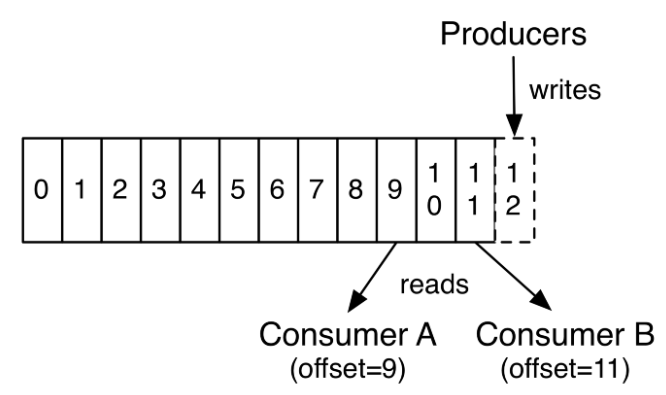
| Producers 與 Consumers 分別對應 publish/subscribe 系統的概念,
Producers 可以新增資料到 topic,Consumers 負責從資料讀取 topic。
|
![]()
Brokers and Clusters
1
2
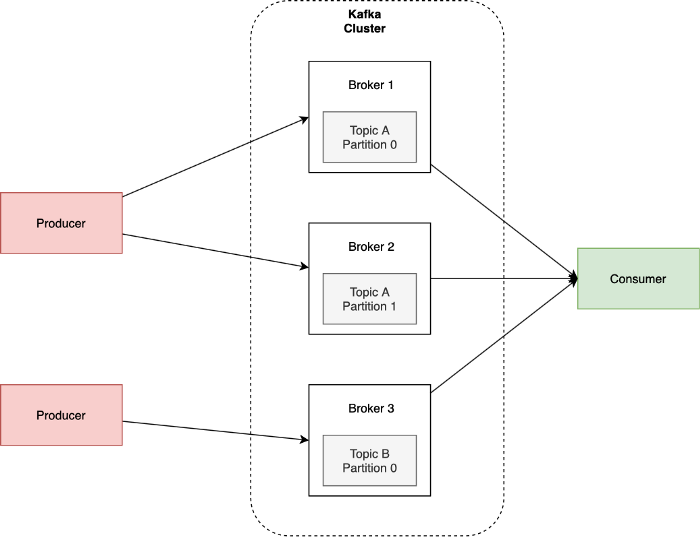
| 一個單台 Kafka server 稱為 broker,每個 broker 接收來自 producers 的訊並寫入至磁碟中,同時回應來自 Consumers 的資料請求。
多個 Brokers 連接在一起稱之為 Cluster,Cluster 中存在一個 controller (動態建立),負責分配 partitions 與監控 brokers 狀態。
|
![]()
Retention
1
2
| Retention 是指 Kafka 可以設定的存放在磁碟中的一段時間,預設是 7 天或是資料量大於 1 GB 就會自動刪除一些資料。
Kafka 可以針對不同 topic 設定不同 Retention。
|
Multiple Clusters
1
2
| Kafka 支援 Multiple Clusters,主要是為了可以提高可用性與安全性,
如建立cluster 於不同的資料中心,並提供了稱之為 MirrorMaker 的工具讓你輕易在 clusters 之間複製資料。
|